About Me
I am currently an Applied Research Scientist on the Trust and Safety team at Alberta Machine Intelligence Institute (Amii). Before Amii, I completed my PhD at Toronto Metropolitan University under the supervision of Nariman Farsad and Isaac Woungang. My PhD work examined how to improve the capabilities of multi-task reinforcement learning agents in scenarios where a single policy must accomplish multiple tasks. Previously, I completed my MSc in Computer Science at Brock University under the supervision of Beatrice Ombuki-Berman, and I received my BSc. in Computer Science from Trent University.
Research
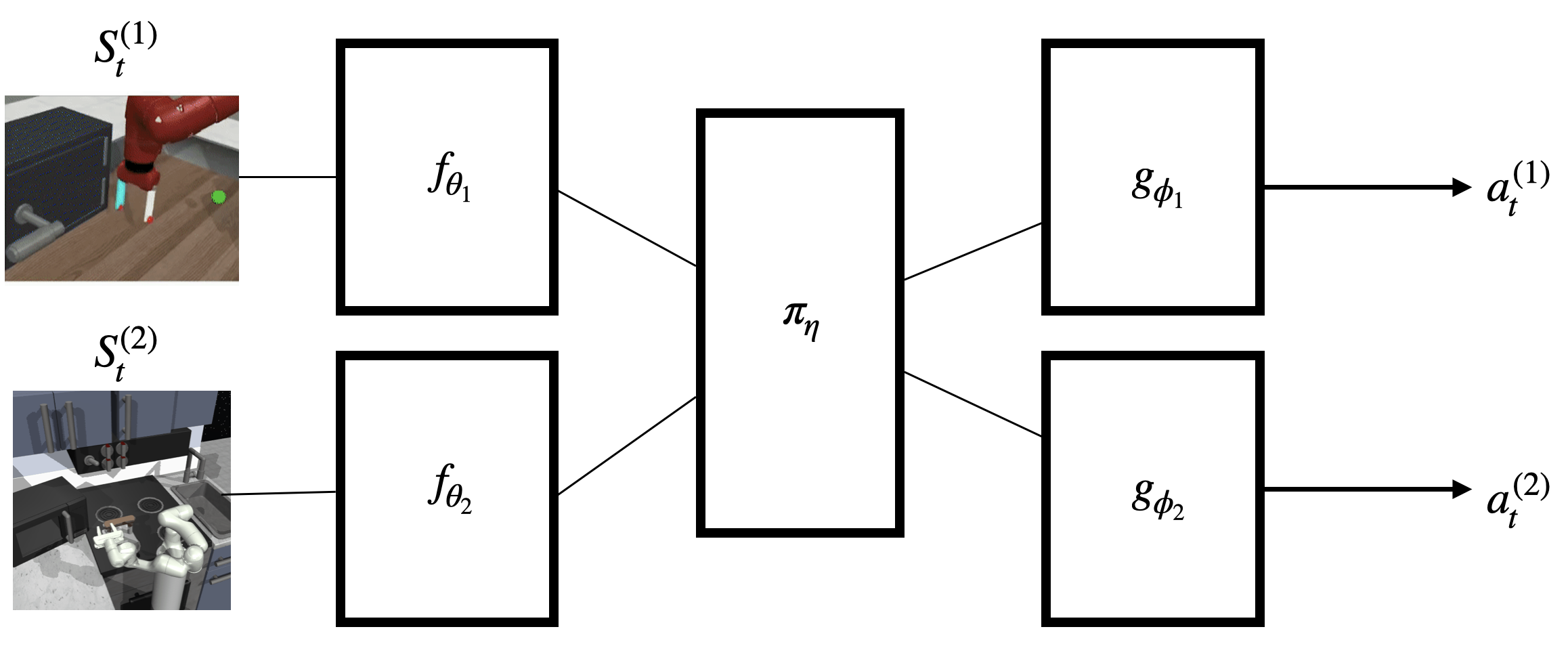
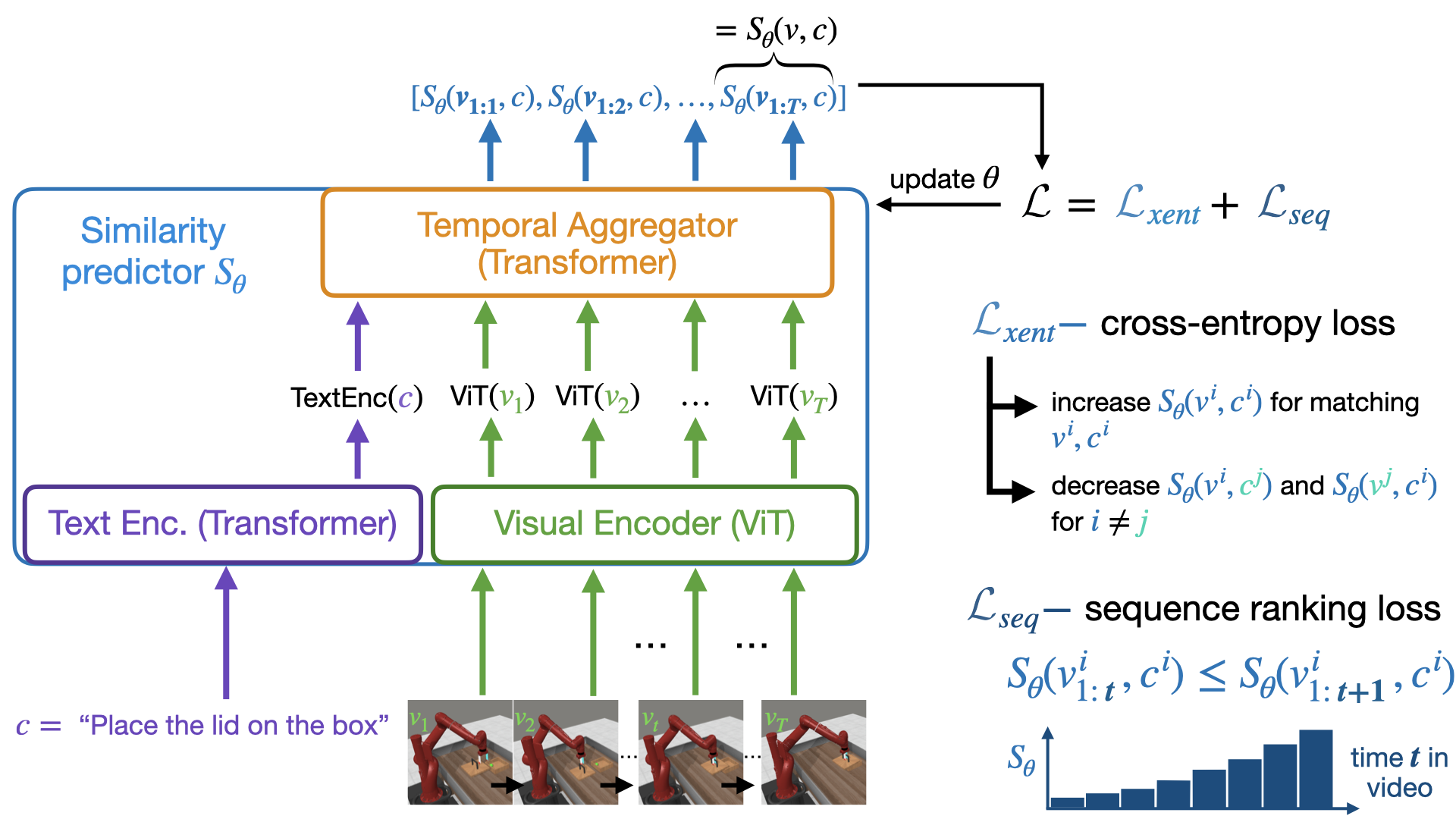
My current research focuses on the reliability, robustness, and trustworthiness of reinforcement learning. This includes both using RL to perform automated safety testing (e.g. automated red-teaming) or doing research in RL specifically looking at performance beyond episodic returns.
Past Experience
Before joining Amii, I was a part-time lecturer in the Computer Science Department at Brock University. Previously, I was an intern at Royal Bank of Canada working on supporting their technical infrastructure using AIOps methods. Upon the completion of my MSc, I was the Lead Machine Learning Developer at Castle Ridge Asset Management.
Publications




reginald k mclean at gmail dot com
Department of Computer Science
Toronto Metropolitan University
Toronto, Ontario
Canada